The AI Revolution - Where We Are and Where We're Going
It's December, 2024. At this critical juncture at the precipice of Artificial General Intelligence, I wanted to put down some thoughts that describe the AI landscape from my perspective as an investor and builder in the space. I'm excited at the opportunity to correct my wrong takes as the picture becomes more clear.
I. Setting the Stage: The Third Wave of AI
The History and Context
We're in the "third wave" of AI. The first wave dried up in the 1960s, due to a fundamental overstatement and misunderstanding of what algorithms could accomplish at the time.
The second wave petered out in the 80s, not due to a misunderstanding, but a fundamental lack of computing power.
Now we have the compute. In the current AI wave, the math from the second wave is largely the same, it's just that we can now transmute the equations from theoretical to applied.
Why This Time is Different
That's not to say that mathematical innovation isn't still happening. Generative AI approaches like transformers (language) and diffusion models (vision) are brand new in the third wave. Their growth in terms of practical application is still very early, and largely untapped.
Early Stage vs. Late Stage
All AI companies are early stage. If you asked the average technologist what "AI" meant in 2014, they would describe chaining together logic gates, and algorithms. True artificial intelligence was largely an academic pursuit, with the "product" being a whitepaper. It's a lot different now. To illustrate this point further: you know the AI juggernaut that's changing the world, one chat session at a time? I don't even need to name it, you already know it's OpenAI. It was founded only in 2015!
This is anyone's game. A team of seven at Google invented the transformer, the foundational piece of technology that all modern AI is built from. Today, all of them are either running fledgling edge AI companies, crypto companies, or are back at Google, or OpenAI.
Safetyism vs. Techno-Optimism
Modern AI formed at DeepMind, a staunchly academic outfit.
Google acquired DeepMind in 2014. Under Google, the DeepMind academics became worried about Google misusing the tech, selling it to questionable entities, so they attempted to split DeepMind out again.
That attempt failed, so the main folks quit and formed OpenAI.
Under OpenAI, the academics again became worried about OpenAI misusing the tech in the wake of AGI, so they quit to form Anthropic.
Anthropic, realizing that a staunch safetyist posture would guarantee their insolvency, has moved closer to OpenAI's position of building for consumers in service of revenue.
There are no serious figures who are truly interested in safetyism from an investment standpoint.
Critical Success Factors
The traits of successful AI companies include:
- Easy access to capital
- Easy access to energy
- Easy access to metal
- Easy access to training data
- Working on world-class problems
- …which attracts world-class talent
II. The Race to AGI
Defining AGI
It's worth noting that the definition of "AGI" is changing. The goal posts keep getting moved. It evolved from "doing most tasks as well as the average human" to "doing most tasks as well as the best humans" to "doing all tasks better than any human."
In only the last couple of years, we've seen the chasm get crossed here. It's fair to say that AI can structure unstructured information better than any human.
The path to AGI is about each task hurdle being jumped, not a singular point in time.
The Building Blocks
Compute Requirements
Computing power can serve as a useful proxy for human brain capability:
- GPT4, finished training in 2022. 1.76 trillion parameters at 100 megawatts.
- Human brain, 100 trillion synapses at ~15 watts.
Doing some napkin math, that means current GPT models will need to become 100X more powerful to achieve brain-scale intelligence, assuming we don't identify efficiencies along the way.
An aside: how incredible is the human brain? 15 watts! Millions of years of evolution will do that to ya.
Parameters and synapses are not perfectly comparable, of course. Humans are incredible at reasoning, yet have a context window of about 10,000 tokens. GPTs have a context window of 2 million+ tokens, yet can't reason. The synapse vs. parameter comparison does at least indicate the scale of the computing power required.
Energy Requirements
xAI's training cluster, argued to be the world's largest, is estimated to require 150MW of energy. Extrapolating, a brain-scale GPT would require 1 gigawatt of energy, about half of the output of the Hoover Dam, or the average capacity of a nuclear power plant, exclusively.
How much does it cost to build a nuclear power plant? $5 billion dollars. To your run of the mill billionaire, or state actor, that's cheap! Capital isn't the problem; government approval is.
Needless to say, building the infrastructure just to train a brain-scale model will be a monumental undertaking.
Capital Requirements
The cost to train GPT4 was estimated to be $500M, but that number has dropped dramatically. One could train a GPT4-scale model from scratch today for $50M. The efficiencies are likely to continue, especially with the launch of the NVIDIA H200 and ongoing chip development.
Record-levels of private capex is being deployed for this purpose, and companies like Google are effectively "betting the company" on reaching AGI first.
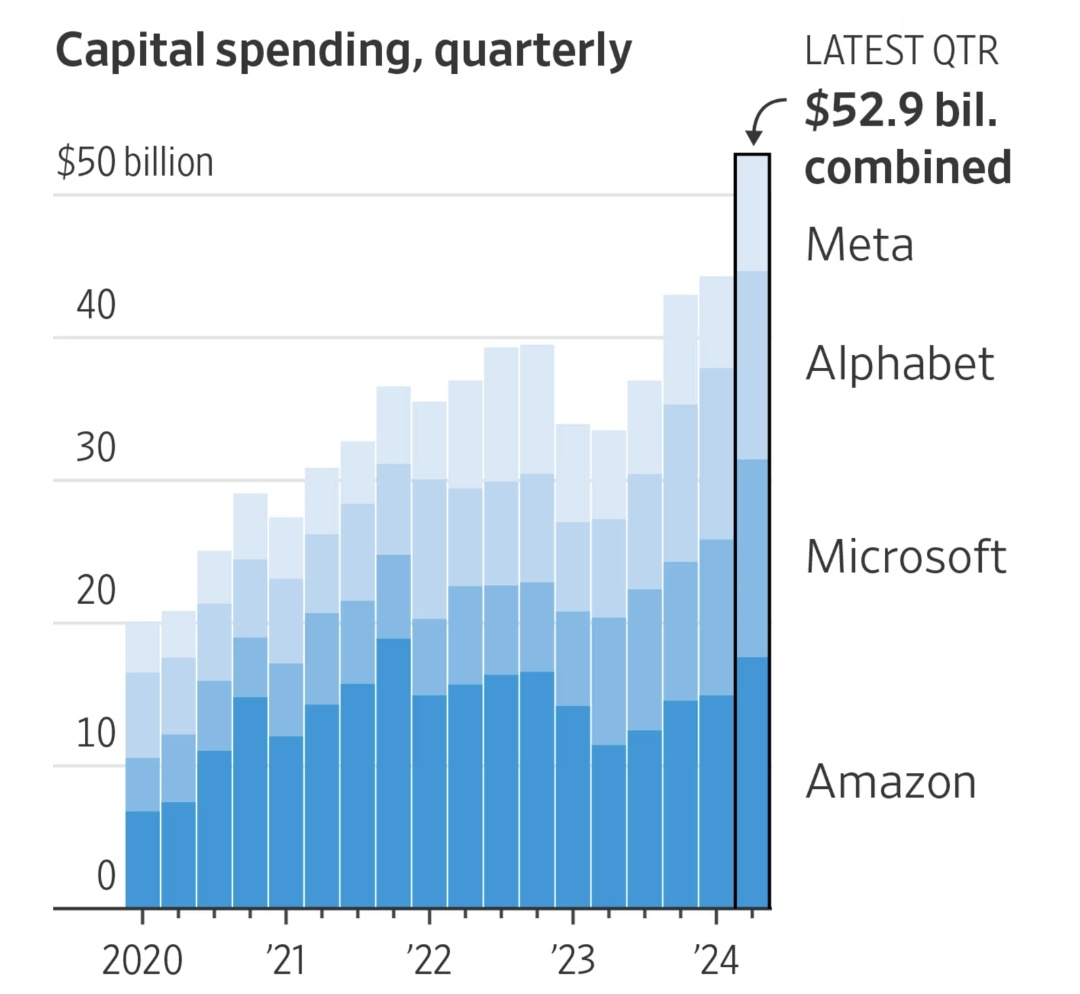
Global Competition
The race to AGI is on. In many ways, it's a zero-sum game. I'm optimistic at the odds of AGI being American, with democratic values.
Congressional dysfunction is a feature, not a bug. Regulation that is on the table, like California's SB1047, isn't onerous. Frontier AI companies are already in compliance, and don't have to slow down.
That said, the EU is DoA. The AI Act has completely nerfed their ability to be competitive. In some cases, if you want to develop a new model in the EU, you need to write a letter to the government, and get their approval, before you can write a single line of code. Non-starter.
China is strong from a compute standpoint, but because so much of it is state-driven, there's lower risk of brain drain.
Other serious players, like Saudi Arabia, are willing to throw their oil money at the problem, and have gained a measurable foothold, having the opportunity to invest in all of the major frontier AI companies. The solace I take here is that it's not a first-party pursuit, and the funding has contingencies, like they get access to the tech but don't have outright control of the tech. Absolutely a cause for concern, nevertheless.
III. The Business of AI
Business Models and Monetization
It is difficult to say exactly how to quantify the value of AI, as it touches everything in big and small ways. There are three lenses to view the business of intelligence through:
- as a raw utility, like electricity, or water (or even more significant, the air we breathe)
- as a product, like ChatGPT, Gemini, Claude, or a custom model for a business.
- as a service, like a consulting firm, or a platform company (this includes wrappers, using AI as a tool to do something else)
Through those prisms, it's clear that every single industry will be transformed by AI. It's already begun. Agriculture, energy, natural resources, manufacturing and construction, tech and communications, services and consumer industries, government, real estate, and infrastructure. All of them will change significantly.
AND
Intelligence per se, something we've never been able to commoditize without involving humans, will be an industry for the first time in human history.
So what is the value of "intelligence" in our society? It's like a brand new utility with trillions of dollars of potential, applied horizontally. All we can say is that we know it's worth something, probably a lot.
The arrival of AGI is a whole other step change. What is the pharmaceutical industry worth when cures to long-term diseases are created every hour? Does it get priced in quickly, or will we be constantly getting our baselines reset? Sociologists and historians will be the best predictors of how the world will adapt. We humans haven't adapted to respond to societal changes this rapid, so we'll either artificially nerf the changes so we can accept them, or succumb to chaos, regardless of how positive the outcomes are.
Exit Strategies and Long-Term Vision
What are the potential exit strategies for investors in frontier AI companies, and how does a company's long-term vision align with sustainable growth and investor returns?
Similar paths to other companies:
- Acquihiring
- Consolidation
- IPO
Market Readiness and Adoption
Everyone is "looking at" AI, but a relative few have adopted it beyond getting ChatGPT to write memos. Early days.
Evaluating Market Readiness
This isn't as intuitive as one might think. High-risk, high-reward tech startups are naturally all-in on AI, but so is one of the most risk-averse industries in the world: legal. The world of legal discovery has been completely reinvented, with even the smallest firms proudly trumpeting their full-throated support of AI, liberally dumping pallets of case law papers into LLMs (great training fodder) for a nice chew.
But other industries, like finance, are slow on the take, and "stock market predictors" aren't performing as well as one might imagine.
If there's one "rule" I'd apply for assessing market readiness it's this: does the industry suffer from a large amount of unstructured knowledge? If so, they stand to gain the most from AI, and should adopt it most readily.
Adoption Barriers
The barriers of AI adoption aren't technical. The UI of LLMs couldn't be simpler. If you can chat with a human, you can use AI. What seems to stall out adoption is a concern over data security (rightfully). Industries that deal in sensitive information (government contractors, three-letter agencies), will be the last to adopt AI, simply because they only have the option to train their own models, which requires hundreds of millions of dollars in compute, and the talent to train the models. Kind of impossible at this point, but accepting a private frontier model remains untenable.
Investment Landscape
The Reality
With early stage comes more speculation, risk, and upside.
From a different angle, let's say "stage" is a reflection of valuation and not age. As an investor, it's pretty hard to get in early enough to generate meaningful ROI. Pre-product companies are raising $150M at $1B valuations. Angels will be waiting a long time for that $150K check to turn into $300K.
These days, without an established network and a specific thesis, there is very little alpha to be gained if one were to invest directly in an AI company, unless it's a Friends & Family raise.
How I Find Investment Opportunities
I have a specific thesis that I'm confident separates the "real ones" from the grifters. If you're interested in learning more, reach out.
Timing and Maturity
The next five years will be a boon for wrapper companies. They're not going to last long-term, so you'd be right to say that wrapper companies will fail. But not for (at least) five years. Until then, do you want to be right, or do you want to make money?
Once AGI hits, nobody knows what happens.
Red Flags in AI Investment
Hype is the biggest thing I'm paranoid about succumbing to. That hype exists at all for AI is not per se a cause for alarm. Many folks conflate the hype around crypto with the hype for AI.
But with crypto, the hype was always rooted in "get rich quick" schemes, taking advantage of the greater fool. To this day, its technical application is extremely limited, reserved almost exclusively as a financial instrument with a small developer community, and a lack of real-world use cases.
With AI, all stand to gain. There is no "fool" to exploit. It will simply be. It's right to be excited about, but many grifters are leveraging this hype to fund something they are unqualified to shepherd, or do not understand.
How to Spot AI Grifters
There are always exceptions, and one could argue I'm leaving money on the table by disqualifying opportunities using the criteria below. I can't win 'em all, but I'll still sleep at night.
The founding team has someone who did anything with crypto after 2012. This is a strong indicator that they're just hype chasers, with no regard for the substance of what they're working on. Except for bitcoin until around 2012, crypto has been a decade-long trap for non-serious figures, imo.
Founding team has someone who did ML or other pre-transformer AI work, like "expert systems." This is counter-intuitive. Isn't having a PhD comp sci person involved a golden ticket? No. I've seen many AI companies try to have a veteran AI technician serve as a shibboleth for being cutting edge, but it doesn't translate. It's like having a WWII fighter pilot in your F-35 squadron.
"Quantum AI." Run. They're just buzzwords. Quantum computing conceptually is still trying to hold bits in memory for more than a thousandth of a second. The fundamental mechanism for training models depends on huge amounts of memory with a crucial dependence on error-checking. Quantum AI? No such thing.
Robotics/androids. We're still in the world of Boston Dynamics; robots doing backflips as marketing for the next raise. Lots of capital being invested here, but it's too early.
 ^ this guy tweeted this a year after raising $675M at $2.5B pre-money. Good to stay curious, I guess.
^ this guy tweeted this a year after raising $675M at $2.5B pre-money. Good to stay curious, I guess.
Yellow Flags in AI Investment
AI-first content generation. The demand for “Taylor Swift in a Seinfeld episode” is overstated, imo. I'm not sure it drives the market. People want shared experiences with each other, not one-of-one. We will absolutely see AI being used as a tool in entertainment, but 100% AI slop sounds gimmicky with low long-term value. I'm sure I'll be proven wrong here.
For practical SaaS, companies that use AI in their marketing headline, i.e. “it’s sales, but with AI!” Having AI in your software these days is table stakes. It's like saying "we're software, but in the cloud!" What does the AI enable you to do? This isn't a deal breaker, sometimes it's just good marketing. Salesforce does this, and I'm sure benefits greatly.
A lack of product vision. Startups that pitch on buzzwords without a substantial technology plan are unserious. The danger of inflated valuations not backed by fundamentals - every AI company is raising $5M at $25M pre-money with no product, and it only goes up from there. A down round in the next 18 months seems inevitable for companies like this. But do you want to be right, or do you want to make money?
Technical limitations. Overpromising on AI capabilities that are not feasible with current technology fundamentals. For example, you can't trust AI for math, facts, or current events due to the tokenization problem. Until that gets solved, major walls are up in those spaces. Robotics companies are guilty here, too.
Dependency on third-party technologies without proprietary innovation. In other words: wrapper companies. This is not a deal breaker, but wrapper companies do have a limited shelf life. In five years, they will be a commodity.
Ethical negligence. I'm not as worried about this, as the US is very slow to regulate (see below).
Elements not unique to AI. A lack of market understanding. Teams that do not grasp the industry they aim to serve - AI first, domain expertise second. There's lots of opportunity if it’s flipped around. Ignoring customer feedback and market signals. Hubris means insisting on the initial vision and not what customers are willing to pay for.
IV. The Technology Stack
Current State of the Art
Large Language Models
SaaS is synonymous with software. There's virtually no modern software you can buy that is a perpetual license and not a subscription.
Software will continue, with AI at its core. Having AI incorporated into your product will not be the differentiator – what customers and users can do with the combination - will be.
Software ultimately is about structuring data, gluing it together, and storing those relationships. That doesn't change. With AI, it gets even stronger, as it can make heaps of unstructured data structured for the first time. Long-standing relationships, which were hiding in plain sight, will be uncovered.
Vision Models
Vision Transformers are a significant development in the field of computer vision. These models use transformer architectures, originally designed for natural language processing tasks, to process image data. The Vision Transformers' ability to handle considerable amounts of image data efficiently is transforming the landscape of visual tasks, such as image classification and object detection.
Mixture of Experts (MoE) Models
MoE models work by only using the parts of the model needed for each task, which makes them faster and better at specific jobs.
State Space Models (SSM)
SSMs are good at working with data that happens in a sequence, like sentences or time-based information. They can track patterns over long stretches better than older methods.
Reasoning-Enhanced Models
These models are designed to "think harder" before answering, which makes them better at solving tricky problems like math or coding.
Multimodal Systems
These models can handle different types of data, like text, pictures, and sound, all at once. This lets them do more complex tasks by combining what they learn from each type of data.
Emerging Technologies
Edge AI and Edge Intelligence
Edge AI refers to deploying AI models on edge devices, like your phone or laptop. This is particularly beneficial for applications requiring low latency, reduced bandwidth usage, and enhanced data privacy. Imagine what could happen if Siri suddenly got a lot smarter.
Another example: self-driving cars. If your car needed to have a constant connection to the cloud, it would be a disaster.
Federated Learning
Federated Learning is designed to enable decentralized data processing, effectively making a training cluster out of the world's computers. We see examples of this today with blockchains, and is a descendant of things like SETI@Home. It allows multiple devices to collaboratively train a shared model while keeping the data encrypted locally.
Split Learning/Inference
Split Learning is an innovative technique to address the resource constraints of edge devices. The training happens in the cloud, but inference happens on-device.
Technical Considerations
Data Obfuscation
One of the best sources of data for training models is the web. If you haven't noticed, Googling something in 2024 is a bit of a bear. The results just aren't what they used to be. Almost all content is gated, and the results are increasingly less relevant, or advertorial. This means the quality and quantity of data is decreasing, which limits the capabilities of future models.
Energy Bottlenecks
Training models is expensive and increasingly power-dependent. xAI's new training cluster needs an estimated 150MW, which is what's needed to power 150,000 homes. The equivalent of 400,000 solar panels.
Technical Limitations
Overpromising on AI capabilities that are not feasible with current technology fundamentals. For example, you can't trust AI for math, facts, or current events due to the tokenization problem. Until that gets solved, major walls are up in those spaces.
The Role of Open Source
The impact of open "source" AI platforms is minimal. They exist mostly at the inference level, and publish "open weights," not the source data that the models were trained on. In practice, this means nobody can replicate a Llama model (for example) from source. Open models are reserved for hobby developers who don't want to fork over $20/month to OpenAI to use ChatGPT.
The "democratization" of AI is also mostly a pipedream, given the monumental costs required to train novel models. The folks funding that training need to see some kind of nut in return, like a competitive advantage, ROI, or access to the tech.
Zuck has even disclosed his ulterior motive: "We're not pursuing this out of altruism, though I believe it will benefit the ecosystem. We're doing it because we think it will enhance our offerings by creating a strong ecosystem around contributions, as seen with the PyTorch community."
In short, the best way to recruit developers is to give them access to the tech that they want to build things with.
Security Considerations
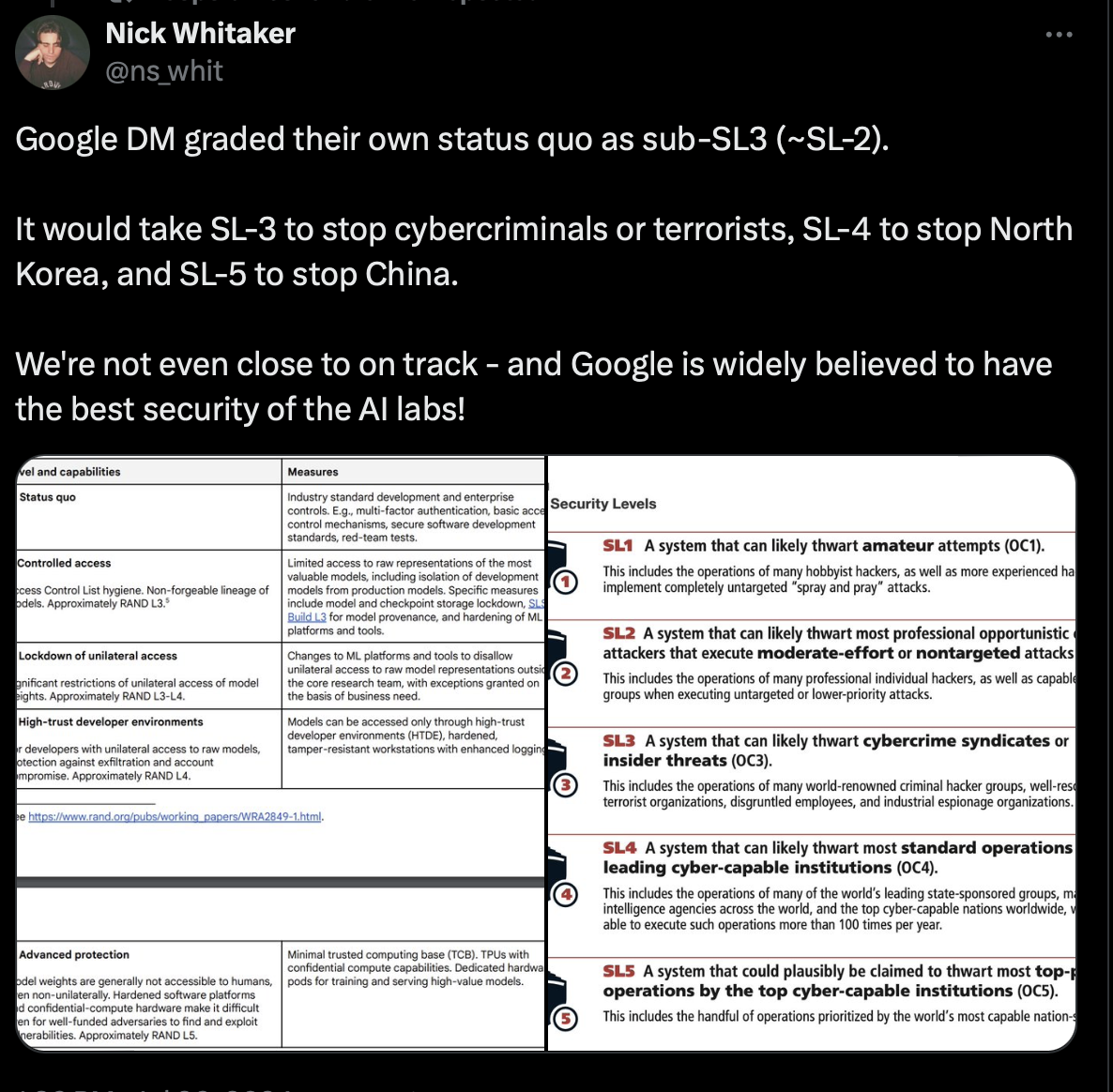
The latest OpenAI models can be jailbroken 64% of the time. It's a very tricky problem to solve, because if you take up too much of the system prompt with jailbreak-proofing, the context window is reduced, and the model's ability to follow any instructions at all is compromised.
Most companies employ industry standard compliance, adhering to standards like GDPR, CCPA, what you would expect from any typical SaaS company. But frontier AI companies have unique data leakage concerns that are rooted in how tokenization works.
Still, the claims of data leakage are overstated. The "data" that is "leaked" is actually a hallucination. The pre-trained model (the model that actually has a direct relationship with the training data) isn't what is actually used by users at the inference level. Inference is decode-only, meaning the model is not given any information about the training data. It's just given a prompt, and it must generate a response. And the prompt itself is not reincorporated into the training data. Not at runtime, anyway. It's certainly being used for training future models like GPT-5.
Ultimately, the most worthwhile use of truly hardened AI is in government and military applications, and could consumer models ever really be good enough for that?
V. On The Frontier
Frontier AI Companies
Differentiation
How do the underlying architectures differ between companies? Competitive advantage goes all the way up the chain. Starting at the last principle and working backwards:
Capacity
Capacity to provide users with a scaled solution (ChatGPT has no cooldowns; Claude does) which supports platform lock-in.
Data
Google has their entire search index, Gmail, YouTube, etc. to train their models on in perpetuity. This makes it all the more embarrassing that Gemini is in last place as a frontier model. OpenAI on the other hand, is completely dependent on third parties for their data, making a deal with Microsoft to help fill the gaps. Yet they're in the lead.
Compute
The better and more powerful the hardware, the faster and more efficiently companies can train their models. Access to large, powerful clusters of GPUs and TPUs is a key factor in staying competitive. It was recently announced that xAI (Elon Musk) has secured a $1.08B deal with NVIDIA to get priority access to the latest GB200 chips as soon as they come off the assembly line.
Expertise
AI companies need deep institutional knowledge of how to train models effectively. This includes designing algorithms that make training faster, cheaper, and more efficient.
Talent
Building cutting-edge AI requires a team of skilled researchers, engineers, and developers. The more talented the team, the better the models they can create. Companies compete fiercely to attract and retain top talent in the AI field, which is why you'll see some individual contributor salaries in the $1M per year range.
Capital
Capital is crucial to retain top talent, buy compute resources, and invest in research. Building leading AI models is incredibly expensive, so companies with more funding have an advantage. Similar to a political campaign, the more you raise, the higher your odds of winning.
Energy
Training large AI models uses massive amounts of energy. Companies need access to reliable, affordable power to keep their training clusters running. We're seeing previous climate change leaders like Google and Meta scaling back their ESG efforts, as they per se restrict the ability to build and train new models.
Policy
Government policies and regulations play a big role in whether a company can build and train AI models. Companies need permission to use large datasets, import advanced chips, and deploy their systems in different regions. Navigating these rules is essential to staying in the game. And as we've seen with the EU's AI Act, a single policy can completely derail a continent's ability to be a player.
All of the above becomes a virtuous cycle; being more useful to users galvanizes governmental support, etc.
Defensibility
How do frontier AI companies position themselves against emerging competitors from both established tech giants and new entrants in the AI space?
High defensibility
Incumbency. Nobody has heard of Anthropic/Claude, so they don't get the usage data for training that OpenAI does to make future models better. Tesla has a fleet of millions of vehicles to train on, where Waymo in a closed circuit.
Talent. AI requires world-class talent. What causes them to leave for another company? The opportunity to do something on their own; to have even more agency. But as we saw with the original creators of the transformer, being an incredible engineer does not a CEO make. Most of the time, if the most talented folks are taken care of, they're not budging.
Efficiency. Like compounding interest, when you can train a model that's smarter than the others for half the cost, your next model will be twice as smart at a quarter the cost.
Infrastructure. Energy grid access; chip forges; distribution
Institutional knowledge. Proprietary algorithms; data sets.
Medium defensibility
- Proprietary data access. - synthetic data and RLAIF means having unique datasets isn't as compelling except in niche applications (i.e. oil drilling flow rate modeling, not generative)
Low defensibility
IP isn't very important, it's like saying you have the patent on the nuclear bomb vs. a country who has built the bomb
Platform lock-in. Switching is incredibly easy for customers. Just point your thing at a new model. Being SOTA is crucial for knowledge work.
VI. Critical Challenges
Regulatory Environment
Congressional dysfunction is a feature, not a bug. Regulation that is on the table, like California's SB1047, isn't onerous. Frontier AI companies are already in compliance, and don't have to slow down.
The EU's AI Act has completely nerfed their ability to be competitive. In some cases, if you want to develop a new model in the EU, you need to write a letter to the government, and get their approval, before you can write a single line of code. Non-starter.
Ethics and Safety
This is an ongoing challenge. Most companies employ industry standard compliance, adhering to standards like GDPR, CCPA, what you would expect from any typical SaaS company. But frontier AI companies have unique concerns:
- Data leakage rooted in tokenization
- Jailbreaking remains an ongoing problem
- Model bias and fairness
- Transparency vs proprietary tech
- Alignment with human values
Sustainability
There is effectively no regard for sustainability at the moment, other than considering building new training clusters near nuclear power plants. Even Musk's new cluster in Texas has a bad carbon footprint.
Many companies are betting the farm on achieving AGI first, so that is getting the priority.
Infrastructure Limitations
- Compute bottlenecks
- Energy grid constraints
- Chip manufacturing capacity
- Data center locations and cooling
- Network bandwidth for distributed training
Data Privacy and Security
- Model training data concerns
- Inference privacy
- Corporate secrets in training data
- Personal information protection
- Cross-border data flows
VII. Looking Forward
Consolidation vs. Diversification
We are a long way out from a consolidation, but the amount of money being invested in model training alone is eye-watering.
New Breakthroughs
Alternatives to the transformer model
What surprised virtually everyone is that deep learning worked. Taking the same old math and just scaling up the compute really did net something new. There remains an open question that continuing to scale transformers is the finish line, or just a stepping stone along the critical path to AGI.
Training efficiencies
The cost to train a GPT-4-class model are plummeting. One could train a GPT4-scale model from scratch today for $50M, down from $500M just a year ago. The efficiencies are likely to continue, especially with:
- Launch of NVIDIA H200
- New training architectures
- Improved algorithms
- Better data preprocessing
New Model Types
- Vision Transformers (ViTs) for advanced computer vision
- Multimodal Foundation Models integrating text, images, audio
- Edge AI and Edge Intelligence for distributed computing
- Federated Learning for privacy-preserving AI
- Symbolic AI and Knowledge Graphs for improved reasoning
- Split Learning/Inference for resource optimization
Societal Implications
The way we trudge through next five years will be much different than the five years after that. Even the most liberal estimates for AI advancement are being beaten. There's a chance things could stall out, barring an unforeseen bottleneck. Even if that's the case, we have a decade ahead of integrating today's incredible AI capabilities into society, the same way it took a decade to integrate the smartphone into society.
VIII. Hard Questions and Open Problems
This section is the least-meaty, and has a lot of unknowns. Being in an incredibly hyped field, it pays to be a skeptic of AI. Not a blind skeptic, of course. One must just properly assess plausibility. If an idea can't stand up to hard questions, there's nothing of value there. Let's ask the hardest questions we can.
I hope to have answers to these things in the coming years.
If not "if," then when?
I don't know. Nobody knows. Anyone who says they do is lying.
You're saying:
But wait Myke, isn't this begging the question a little bit? Why are you acting like AGI is a when, not an if?
That's an excellent question. All I can rely on is my impression of the industry, based on the testimony of folks in the trenches, doing the work. Many (most) of them are conservative when it comes to estimates.
For example, Kurzweil's The Singularity is Near, written in 2005, remains one of the most researched, well-written takes on AI. Near the end of the book is a checklist of what AI might be able to achieve over the proceeding century.
Just a decade and a half later, the checklist is nearly completed.
Inventing AGI in America
There are roughly two hundred people on the planet who have the capability to invent AGI. How can we ensure that most of them are aligned with American interests?
Technical Hurdles
- Reasoning capabilities
- Factual accuracy
- Current events knowledge
- Mathematical computation
- Long-term memory
- True understanding vs pattern matching
- Explainability of model decisions
Economic Impacts
- Job displacement vs creation
- Wealth concentration
- Economic inequality
- Industry disruption
- Market volatility
- Global economic shifts
Existential Risks
- Control and alignment
- Unintended consequences
- Power concentration
- Societal disruption
- Democratic processes
- Information warfare
- Autonomous systems
Unresolved Challenges
- Model interpretability
- Bias and fairness
- Privacy preservation
- Energy sustainability
- Democratic access
- International cooperation
- Regulatory frameworks
- Talent distribution
- Infrastructure scaling
Written on Dec 2nd, 2024